Application Architecture¶
This section contains technical details about the current implementation of the Canadian Aquatic Barriers Database (CABD) back-end application, including feature and vector tile services and the CABD data dictionary. The intended audience are software developers and similar technical users looking to upgrade/maintain the current system or use the API endpoints.
Existing Implementation¶
The current application runs on two Microsoft Azure Java Web App servers, cabd-web (for CABD data) and chyf-web (for CHyF data).
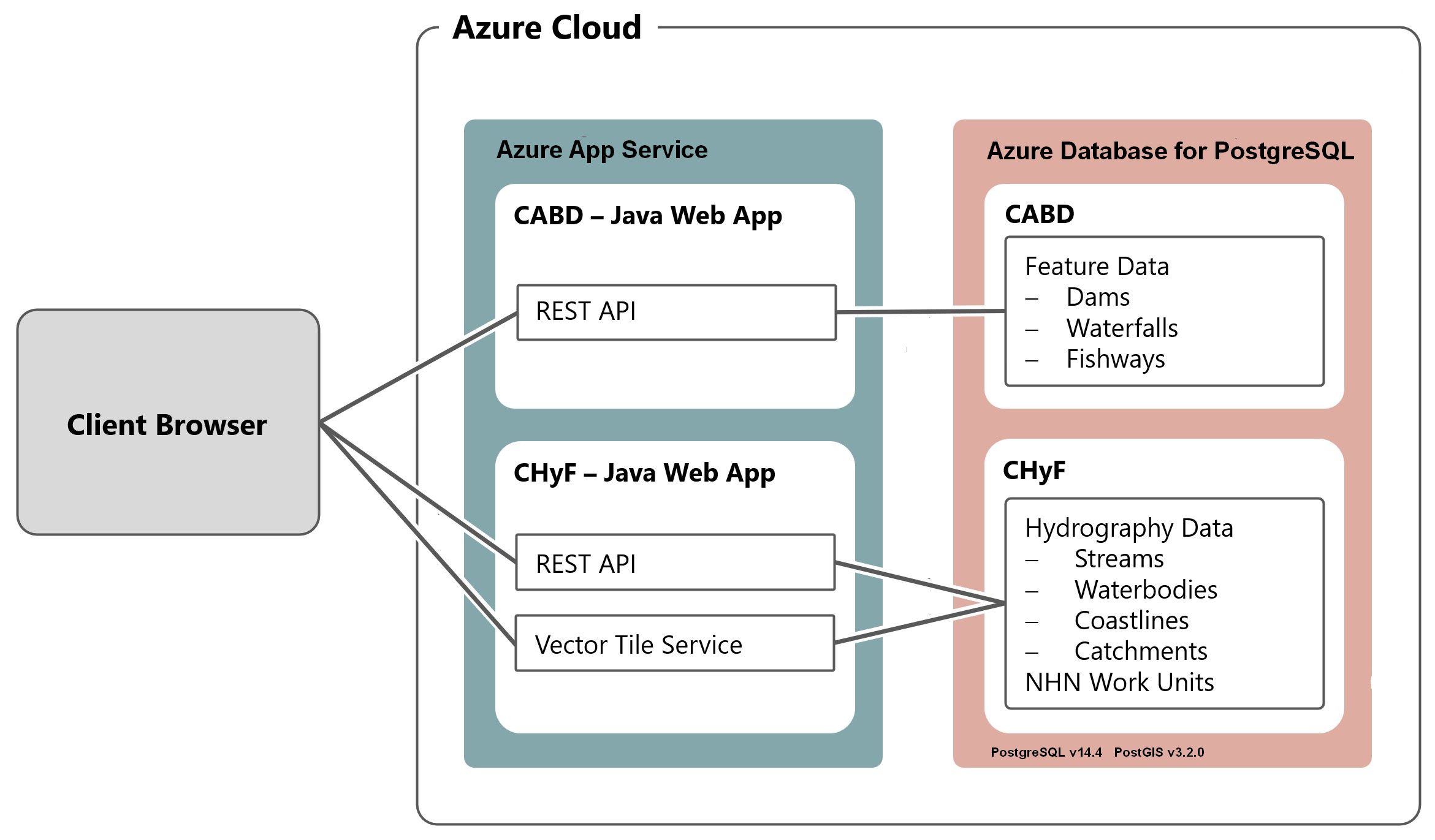
Features and Database Models¶
CABD Feature Model¶
Generic Feature Model¶
Features in CABD have an optional hierarchical structure. Feature types can be combined to form “super feature types”.
There are no structures in the software/database that enforce this model. The database views (see section below) are used to define the various feature types and super types. It would be possible for a feature type to be associated with multiple super types, if desired.
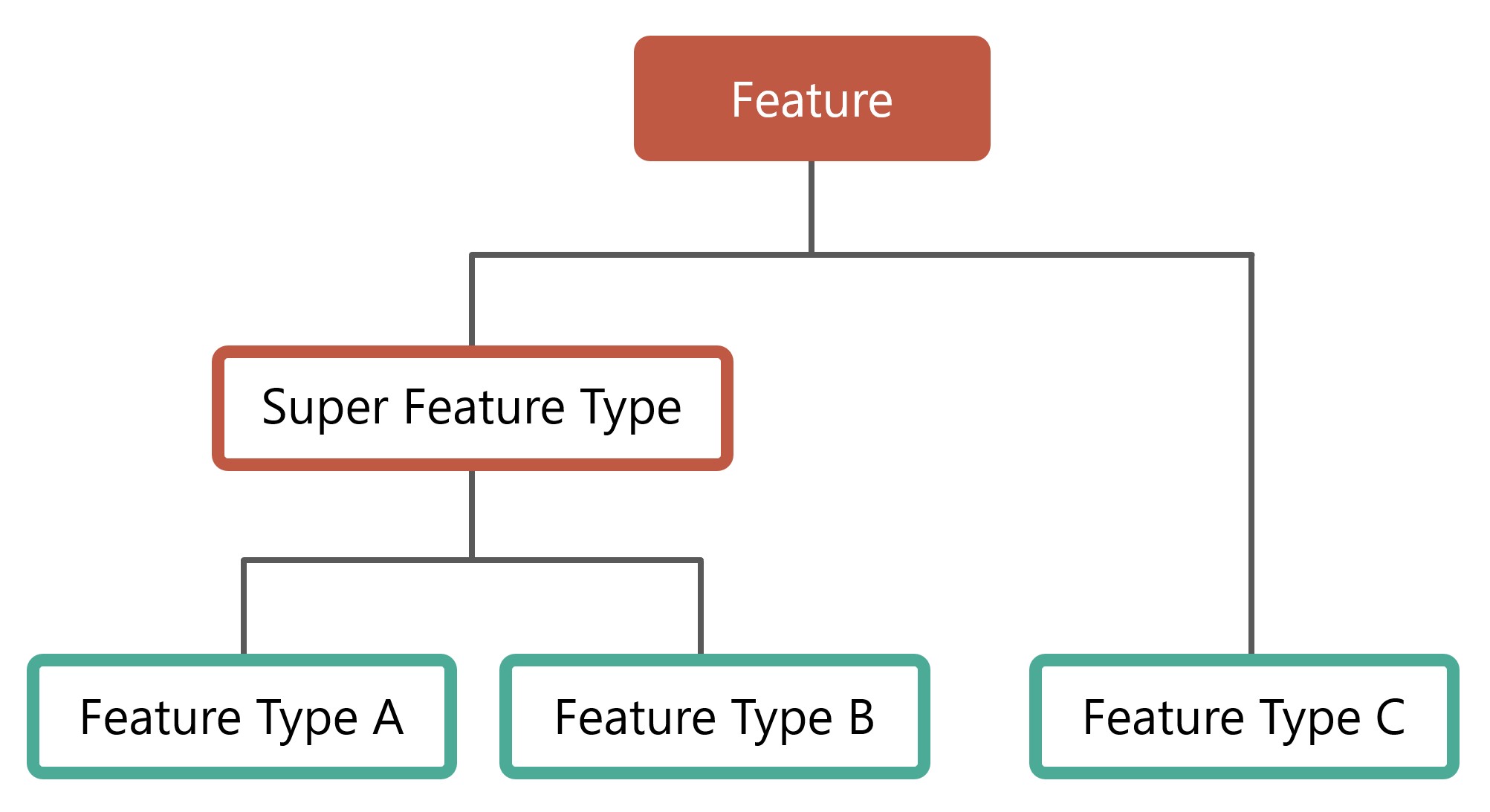
Implemented Feature Model¶
There are currently four feature types and one super type implemented in CABD. Adding additional feature types is expected, and the instructions for this are outlined below (How to add new Feature Type).
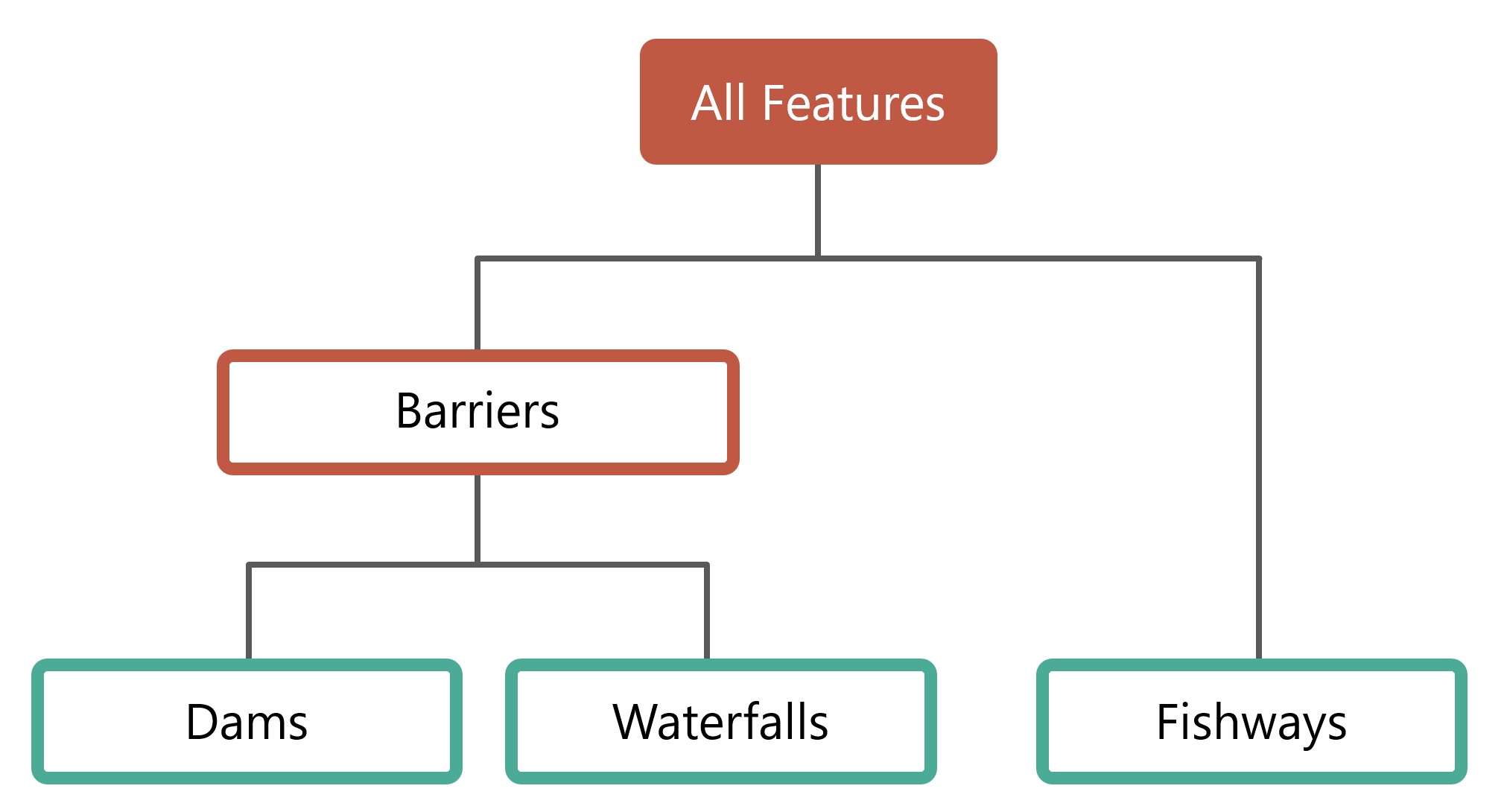
Feature types:
barriers- a super feature type that includes dams, other structures, waterfalls, and modelled crossings.dams- a feature type for features classified as a dam or other structure.waterfalls- a feature type for features classified as a waterfall.fishways- a feature type for features classified as a fish passage structure.modelled crossings- a feature type for features classified as a modelled stream crossing.stream crossings- a feature type for features classified as a stream crossing.
CABD Database Model¶
The database is structured into multiple schemas. Each feature type has its own schema, with a common cabd schema for shared data and feature metadata.
Feature Views¶
Each feature type and super feature type has two associated views which support the API - one view for English (_en) and one view for French (_fr). These views should include all fields required for output (either for display on the UI or to support the future editing API).
The view cabd.all_features_view_<en/fr> supports all feature api endpoints.
Views are used to support the CABD APIs that list features. Each feature type is linked to a database view. When requesting features of a specific type, the view associated with this type is queried. The fields returned by this view populate the attributes of the feature returned by the API. Feature type views will generally query a single data table (for example, the dams view queries the dams data table). Super feature types will generally query multiple data tables (for example, the barriers view queries both the dams data table and the waterfalls data table).
Feature Update View¶
By design, each feature includes an updates_pending attribute that is populated with true or false depending on if there are feature updates pending review in the system. This field is populated by the system using the cabd.updates_pending view. This view should return a single column, cabd_id, for each feature that has a review pending in the database.
Core Tables¶
These tables are the core tables for the system and required regardless of the feature types loaded. They support the definition of feature types.
cabd.feature_types
Lists all the feature types supported by the system.
Column |
Description |
|---|---|
type |
Unique identifier for feature type. Required. |
data_view |
The root name of the data view supporting the feature type. This is the view name without the language suffix (ex. dams_view). Required. |
name_en |
The English human readable name for the feature type. Required. |
name_fr |
The English human readable name for the feature type. Required. |
attribute_source_table |
The data table containing the attribute data source information for the feature type. This is optional and can be null. |
default_featurename_field |
The field in the data_view that represents the main feature name. |
feature_source_table |
The data table containing a link between the features and the data source information. This is optional and can be null. |
data_version |
The version number of the data for the feature type. This version number is included in exports. |
description |
A description of the feature type |
data_table |
The name of the table(s) that contain the official feature data. |
community_data_type |
The name of the community data staging table. Data submitted via the community data api will be placed in this table. |
community_data_photo_fields |
List of photo fields for the community data. Any json keys that match one of these strings will be considered photo data and parsed into an image file and places on the Azure blob storage. |
cabd.attribute_set
Lists the attribute sets supported by the system. Attribute sets allows user to specify which attributes they want included in API results that list features.
- Notes:
The attribute set should not have the name “vectortile”. The system generates a vectortile attribute set automatically that is linked to the include_vector_tile field in the cabd.feature_type_metadata and used for the vector tile service.
The attribute “url” which provides a url to link to the full CABD feature is included in all JSON output for all attribute sets. There is no option to remove it. It is NOT included in other export formats (shape, geopackage, kml).
Column |
Description |
|---|---|
name |
The unique name of the attribute set. |
ft_metadata_col |
The name of the column in the cabd.feature_type_metadata table that identifies which attributes are to be included and in what order. This column must exist in this table with values 1..n for attributes to be included in the results or null for attributes to be excluded. |
cabd.feature_type_metadata
Lists all the attributes for a given feature view and the metadata details about the attribute.
Column |
Description |
|---|---|
view_name |
The data view name. |
field_name |
The field name in the data view that represents this attribute. |
name_en |
The English name of the attribute. |
name_fr |
The French name of the attribute. |
description_en |
An English description of the attribute. |
description_fr |
A French description of the attribute. |
is_link |
Boolean. If true this attribute will be treated as a URL in the API. The value will be returned in URL format (for example: link to another feature). |
data_type |
The data type for the attribute. Valid values: varchar(xxx), text, boolean, array(type), integer, double, uuid, date, geometry. |
value_options_reference |
For columns that have a defined list of valid values in another database table (for example: The string should be of the form For example: |
is_name_search |
True if field to be included in the name API search. Should be set to true fo any attributes that represent the feature name or want to include when searching by name. |
shape_field_name |
The field name for shapefile exports of features. |
vw_<attributeset>_order |
Metadata for the UI. These fields represent the order the attribute should appear in the ui for a given attribute set. The value should be null for attributes to be excluded from the results for the given set. There should be one column for each attribute set listed in the cabd.attribute_set table. |
include_vector_tile |
Boolean. If true, this attribute will be included in the vector tile service. |
cabd.data_source
Lists data sources. Supports data source tracking for feature type attributes.
Column |
Description |
|---|---|
id |
A unique identifier for the data source. |
name |
Name of the data source (matches short names listed on the data sources page). |
version_date |
Data source version date. |
version_number |
Data source version number (optional). |
source |
A link to the source data or full reference and description of where the source data came from. |
comments |
Any additional comments about the data source. |
source_type |
Type of data source (spatial or non-spatial). |
A list of contacts relevant to the CABD database. Currently, contacts are only created when a user submits a feature update.
Column |
Description |
|---|---|
id |
unique system-generated number |
User’s email |
|
name |
User’s name |
organization |
(Optional) Organization associated with the user |
datasource_id |
(Optional) Link to the cabd.data_source table, which represents the datasource associated with this user. |
cabd.user_feature_updates
Users can use the Features API to submit updates to features. All submissions are stored in this table.
Column |
Description |
|---|---|
id |
unique system-generated identifier |
datetime |
Date time of submission |
contact_id |
Link to the contact who submitted the change |
cabd_id |
Link to the feature the update references |
cabd_type |
CABD feature type |
user_description |
The user provided a description of the update |
user_data_source |
The user provided data source |
status |
Internal field representing the status of the update. This is managed by the CABD administrators. |
Shared Attribute Tables¶
All of these tables store data that are shared between multiple feature types. Generally, each of these tables have a unique code (for references), a name, and a description.
cabd.barrier_ownership_type_codescabd.fish_speciescabd.nhn_workunitcabd.passability_status_codescabd.province_territory_codescabd.upstream_passage_type_codescabd.census_subdivisions
Feature Tables¶
The feature type data tables are found in their corresponding schema. Generally, there will be one feature data table and a number of reference tables that represent attribute values. Details for current feature types can be found in the Data Dictionary document.
Feature Type Attribute Data Sources¶
The CABD database has the option of storing the data source for each attribute associated with the feature type. This has been implemented by having <featuretype>.<featuretype>_feature_source and <featuretype>.<featuretype>_attribute_source tables for the feature type (e.g., dams.dams_feature_source and dams.dams_attribute_source).
For each cabd feature, the <featuretype>_feature_source table contains a link to the data sources and associated data source feature ids that the feature was found in. For example, a dam feature that was found in both the nrcan_canvec_mm and bceccs_fiss data sources would have two entries for its cabd_id in the <featuretype>_feature_source table.
<featuretype>_feature_source
Column |
Description |
|---|---|
cabd_id |
The unique cabd feature identifier. This id must exist in the corresponding data table for the feature type. |
datasource_id |
A link to the data source id in the cabd.data_source table |
datasource_feature_id |
The identifier of the feature in the data source. |
The <featuretype>_attribute_source table contains the cabd_id and one column for each attribute that requires data source tracking. The column, <attribute>_ds, links to the cabd.data_source table to identify the data source for the attribute value.
<featuretype>_attribute_source
Column |
Description |
|---|---|
cabd_id |
The unique cabd feature identifier. This id must exist in the corresponding data table for the feature type. |
<attribute1>_ds |
A link to the data source id in the cabd.data_source table that <attribute1> comes from for the feature. |
<attribute2>_ds |
A link to the data source id in the cabd.data_source table that <attribute2> comes from for the feature. |
Community Data¶
The community data API supports the collection of data from community users. This API was developed to be used in conjunction with the Mobile Data Application.
The data submitted to the community API immediately gets written to the cabd.community_data_raw table without any validation or processing. A separate job takes data from this community data table, parses the feature type, photos, and user information and places the photos onto the azure infrastructure, and the remaining data into the appropriate feature staging table in the database. Any features provided without a cabd_id are assigned a new one. Once in the feature staging table it is up to Data Reviews to review the data and update the appropriate CABD features.
Community data submissions can include images. These images are expected to be provided in the JSON as base64 encoded JPEG files. The processing of the raw data includes converting this data into a jpeg file which is placed on the Azure blob storage. The name of the file is referenced in the parsed json data.
cabd.community_data_raw
Column |
Description |
|---|---|
id |
The unique system assigned identifier |
cabd_id |
Link to the cabd feature to be updated. If this doesn’t match any existing cabd_id features then this should be considered a new feature. |
user_id |
The id of the user who submitted the data (references cabd.community_contact) |
uploaded_datetime |
The date/time of the submission |
data |
The data submitted. This is a json object containing the original data with processed image data. Image key/value pairs in the JSON reference a filename of the image which is stored on the Azure blob storage. |
status |
The status field that should be managed by the data reviewers. By default the value is ‘NEW’ but after the data has been reviewed this should bc updated to any other value. |
Community data users are stored in a separate cabd.community_contact table.
cabd.community_contact
Column |
Description |
|---|---|
user_id |
The unique system assigned identifier |
username |
The username/email of the community user |
Each feature type supported needs a feature staging table (<featuretype>_community_staging). This table name is specified in the cabd.feature_types metadata table. Each feature type staging table has a status column. By default the value is NEW. Once the data has been reviewed and appropriate features created/updated, this status column should be updated to something other than NEW.
<featuretype>.community_data_<feature_type>
Column |
Description |
|---|---|
id |
The unique system assigned identifier |
uploaded_datetime |
The date/time the data was submitted |
data |
The raw data submitted |
status |
The system managed status field (one of NEW; PROCESSING; DONE) |
status_message |
A message describing the processing status |
warnings |
A list of warning messages generated during processing |
Each cabd feature has an updates_pending flag, and this flag includes features from the community data staging table that have a status of NEW.
Ghost features are features which have been submitted to the community data API without a cabd id and have not yet been reviewed and added to the official feature dataset. These features also rely on the feature type community data stating table status column (only features with a status of NEW will be considered for ghost features).
Audit Log / Change Tracking¶
The CABD database has tracks changes to the following tables:
cabd.contacts
cabd.fish_species
cabd.data_source
dams.dams
dams.dams_attribute_source
dams.dams_feature_source
waterfalls.waterfalls
waterfalls.waterfalls_attribute_source
waterfalls.waterfalls_feature_source
fishways.fishways
fishways.fishways_attribute_source
fishways.fishways_feature_source
fishways.species_mapping
New feature types can also include change tracking by applying the appropriate triggers to any new database tables that require change tracking.
All changes are logged in the cabd.audit_log table. This table has the following columns:
Column |
Description |
|---|---|
revision |
Unique incrementing revision number |
datetime |
The timestamp of associated with the change |
username |
The user who made the change. This is the postgresql user who made the change |
schemaname |
The schema of the modified table |
tablename |
The name of the modified table |
action |
INSERT, UPDATE, or DELETE |
cabd_id |
The CABD feature id if applicable or null if not applicable. This field will be populated for most changes but will not be populated for changes to the contacts, fish_species, and datasources tables. |
datasource_id |
The datasource id if applicable or null. This field will be populated with the table that has a datasource_id field that is part of the primary key for the table. |
id_pk |
The primary key for the row being modified if applicable or null. This field is populated for tables whose primary keys are not cabd_id or datasource_id (for example contacts and fish_species). |
oldvalues |
The original values of the row (before updating). This only includes values that were modified. |
newvalues |
The new values for the row. This only includes values that have been modified. Values that remain the same are not included. |